
Now that I’m able to render all kinds of shapes that I want and transform them in various ways, its time to use our tools to make something. A simple idea is creating an Ant Colony Simulation! The main goal here is to tax the rendering pipeline so that we can justify optimizing our program using techniques such as SIMD and Multithreading. By spawning thousands of ants and rendering thousands and individual entities, hopefully we can achieve that goal and then bring our selves back to an optimized state through these two techniques.
First things first, we need to create a simple set of rules to follow so that the simulation can work properly.
Rules:
– Ants spawn from a single location and wonder around randomly looking for food.
– While ants are wondering looking for food, they will be spawning to_home pheromones so that they can get a general idea of how to get home once they find food.
– Once they find food and start following to_home pheromones, they begin to produce to_food pheromones so that other ants can find the food they just found.
Now that we have a basic system, we should start spawning a large number of ants, somewhere around 100, have them choose a random direction and simply move straight off the screen with a little variance in direction. My ants are going to be represented by an 8×8 rectangle.
After this I wanted to introduce the concept of food so the ants can react to it. When it finds food, it “grabs” it and heads straight home. Once it deposits the food, it goes back to wondering looking for more food.
Now that this simple addition is working, I needed to put a little more effort into the “wondering” mechanic. I needed the ants to have a real forward direction, and be able to rotate smoothly across random increments looking for food or pheromones. But the problem is, I had not established yet what the sensory range looked like for the ant when it came to detecting food or pheromones. Was it simply the forward direction? Was it a triangular cone in front of the ant? What I decided to do was create three sensory rectangles that are laid out in front of the ant. These would be front-left, front, and front-right. If the ant detected something in either the front left or right sensors, it would smoothly rotate towards that direction. For now, I just want the ant to continue to rotate in random directions, but with the power of visualization, I want to make sure that all my three sensors + my forward direction are behaving as expected!
My next step is to create the concept of a pheromone. I want ants to produce these pheromones on a short timer so they can construct a path. I also want these pheromones to dissipate over time. That way I want have them laying around permanently, and it would be more natural as the ants will be able to follow more recent paths. I’ll first focus on producing one kind of pheromone (to_home) as the other (to_food) will behave exactly the same way and won’t take much work to introduce when the time comes. The color of this pheromone will be depicted as purple.
Now that this basic functionality works, I want to start working on the actual behavior we care about. This is how it will work. Ants will spawn from a colony (a centralized location) and will wonder around looking for food while leaving to_home pheromones. Once they find food, the ant will collect 1 food and begin its journey home by following the to_home pheromones to deposit the food. While its looking returning to the colony, it will be leaving to_food pheromones (depicted in teal) to tell other ants the general direction of where it found food. I also want to increase the speed of the ants, as right now they feel a little slow and sluggish in regards to movement and rotation.
The end goal is to have a couple thousand ants running around, so lets try 2500 ants and see how they behave.
First objective accomplished! This is TERRIBLE performance and we need to make some improvements, this is a software renderer at the end of the day and isn’t going to be a powerhouse like any hardware rendering API. Before we get into major optimizations, lets get a rough understanding of how many entities we are working with and maybe we can do some simple things that could help in optimizing this program.
At the moment, we have a large Entity list that contains all of our Entities. If we do some rough math, we have 2500 ants, we have 3 areas of food each containing 2400 pieces of food, and finally each ant is producing pheromones at a 1/4 second interval which roughly translates to about 10k entities a second. Note that these pheromones dissipate over time so there is an upper bound on how many of them can exist at a time. So at its peek we should roughly have around 100k entities up and running at any given time.
The first thing I want to tackle is how my ants look for other entities. At the moment they simply iterate over this list and loop over every single entity. A simple change we can make is to separate out each entity type into its own list. Food list, to_home pheromone list and a to_food pheromone list. In addition to this, we can break our screen into multiple cells and have our ants only look at its own as well as neighboring cells for food and pheromones. This should look something like this.
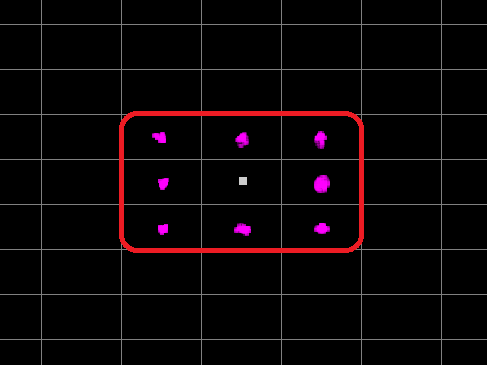
Everything in the range of the red circle should be within the range of what an ant can iterate over and look for. This grid will be 16×16 and each cell will contain its own lists for each kind of entity. All I need to do now is every time I want to spawn a pheromone or food, I simply look at what cell I’m in, and add it to the corresponding list.
Next, lets take a look at SIMD and how we can optimize our rectangle blits. This is my first time working with SIMD so I had to use some solid resources to understand the basics. My two main sources where a few Handmade Hero episodes and Intel’s Intrinsics guide which documents all of the SIMD operations you might need for the family you want to target (In my case I wanted to target the SSE 128bit family).
HMH: https://guide.handmadehero.org/code/day089/#1247
Intel Intrinsics: https://www.intel.com/content/www/us/en/docs/intrinsics-guide/index.html#
For those who don’t know what SIMD is (Single Instruction Multi Data), a brief lame explanation is this. Your CPU has the capability to perform operations WIDE. So taking addition as an example, if you had 4 separate sets of independent additions you wanted do make, you can perform all those additions in a single CPU instruction [A + B][C + D][E + F][H + G]. So in the case of rendering, without SIMD, our general approach looks something like this:
– iterate over an 8×8 region (for Ants specifically)
– grab the existing color and linearly blend it with the new color (with some additional gamma correction)
– write out the new color the buffer
We do this pixel by pixel for each Ant, Pheromone, Food, Colony, everything. But since these pixels are independent from one another (as in we are not doing any anti aliasing or bilinear filtering, although this still works in those cases, its just a little more work), we can do this operation on multiple pixels at a time. Our colors at the moment are 4 channel 32bit values. Since we are using the SSE 128bit family, we can perform all of these operations on 4 pixels at a time. If we were to use a family that supports 256 or 512 bits, we would be able to perform these operations on 8 or 16 pixels at a time.
So when writing out to 1 color could look something like this (reduced for simplicity)
// extract current colors
f32 current_a = ((f32)((*pixel >> 24) & 0xFF) / 255.0f);
f32 current_r = (f32)((*pixel >> 16) & 0xFF);
f32 current_g = (f32)((*pixel >> 8) & 0xFF);
f32 current_b = (f32)((*pixel >> 0) & 0xFF);
// convert to 255 range
color.r *= 255.0f;
color.g *= 255.0f;
color.b *= 255.0f;
// perform linear blend
f32 new_r = (1 - color.a) * current_r + (color.a * color.r);
f32 new_g = (1 - color.a) * current_g + (color.a * color.g);
f32 new_b = (1 - color.a) * current_b + (color.a * color.b);
// write out new colors
u32 new_color = (round_f32_s32(color.a * 255.0f) << 24 | round_f32_s32(new_r) << 16 | round_f32_s32(new_g) << 8 | round_f32_s32(new_b) << 0);
*pixel = new_color;Our code now would look more like this
__m128i loaded_pixel_4x = _mm_loadu_si128((__m128i*)pixel);
// from: argb-argb-argb-argb
// to: aaaa-rrrr-gggg-bbbb
__m128 loaded_r_4x = _mm_cvtepi32_ps(_mm_and_si128(_mm_srli_epi32(loaded_pixel_4x, 16), mask_FF));
__m128 loaded_g_4x = _mm_cvtepi32_ps(_mm_and_si128(_mm_srli_epi32(loaded_pixel_4x, 8), mask_FF));
__m128 loaded_b_4x = _mm_cvtepi32_ps(_mm_and_si128(loaded_pixel_4x, mask_FF));
// linear blend between loaded color and input color
__m128 new_loaded_r_4x = _mm_mul_ps(current_a_percent_4x, loaded_r_4x);
__m128 new_loaded_g_4x = _mm_mul_ps(current_a_percent_4x, loaded_g_4x);
__m128 new_loaded_b_4x = _mm_mul_ps(current_a_percent_4x, loaded_b_4x);
__m128 new_r_4x = _mm_add_ps(new_loaded_r_4x, new_color_r_4x);
__m128 new_g_4x = _mm_add_ps(new_loaded_g_4x, new_color_g_4x);
__m128 new_b_4x = _mm_add_ps(new_loaded_b_4x, new_color_b_4x);
__m128 new_a_4x = _mm_mul_ps(color_a_4x, color_255_4x);
// convert to int, cvtps rounds to nearest. no need for +0.5f
__m128i int_a_4x = _mm_cvtps_epi32(new_a_4x);
__m128i int_r_4x = _mm_cvtps_epi32(new_r_4x);
__m128i int_g_4x = _mm_cvtps_epi32(new_g_4x);
__m128i int_b_4x = _mm_cvtps_epi32(new_b_4x);
// shift argb order
__m128i shifted_int_a_4x = _mm_slli_epi32(int_a_4x, 24);
__m128i shifted_int_r_4x = _mm_slli_epi32(int_r_4x, 16);
__m128i shifted_int_g_4x = _mm_slli_epi32(int_g_4x, 8);
__m128i shifted_int_b_4x = int_b_4x;
// OR everything together
__m128i output_pixel_4x = _mm_or_si128(shifted_int_a_4x,
_mm_or_si128(shifted_int_r_4x,
_mm_or_si128(shifted_int_g_4x,
shifted_int_b_4x)));
__m128i output_masked = _mm_and_si128(mask, output_pixel_4x);
_mm_storeu_si128((__m128i * )pixel, output_masked);
// normally would be 4, but can be less if we reach the end of the rectangle or buffer and want to modify less pixels
pixel += increment;Of course this is a much simpler and redacted version of what is actually in my function for brevity, as there are several edges cases you have to handle such as the last comment in this snippet that talks about having to increment at a different increment from the normal 4 based on whether or not you are reaching the end of your rectangle row or buffer.
Using tools techniques such as __rdtsc() and measuring cycles elapsed, I can see that we were rendering at around 500 cycles per rectangle, and now are down to about 150 cycles per rectangle. I want to note that this program is entirely inefficient and is not meant to run well nor is it meant to run fast. This is partly intentional but not in the sense that I made intentional bad decisions, simply that I didn’t care to write performant code, because I wanted to justify the use for optimization techniques like SIMD in order to noticeably see their value.
The final thing I want to try and tackle here is multi-threading… as of this blog, I hate multi-threading. It has nothing to do with the overall concepts of multi-threading and entirely to do with the C/C++ API implementation being entirely complicated and annoying to work with. But alas we must go down this path to… learn and get better!
The way we are going to do this is simple. We are going to create as many threads as my CPU allows (in this case 24), I will also create a work queue and push “work” on to this queue for the threads to operate on. This will simply be rendering work. So I will push chunks of rendering work and the next available thread will grab that piece of work and operate on it until its done. The work will be everything that needs to be rendered in a single cell from the 16×16 cells that I created earlier.
HANDLE semaphore_handle = CreateSemaphoreExW(0, 0, thread_count, 0, 0, SEMAPHORE_ALL_ACCESS);
for(u32 i=0; i<thread_count; ++i){
DWORD thread_id;
HANDLE thread_handle = CreateThread(0, 0, thread_proc, thread_context.queue, 0, &thread_id);
CloseHandle(thread_handle);
}So once we have these threads up and running, we can simply feed them work by using the semaphore handles that will persist. So instead of having a single buffer that I push render commands to, I’m now pushing to 16×16 buffers (nothing intelligent here or anything I recommend anyone doing. This is just for experimentation and learning), and once there is work to do on those buffers, the next available thread will render my commands!
With all these optimizations done, my ant colony works pretty smoothly with 2500 ants all running around looking for food and bringing it back to the colony!